
Faster delivery of software will fail without a highly engineered Continuous Delivery Pipeline. It not only ensures various application quality attributes, but also allows testing of the release workflows and practicing the delivery of software.

Continuous Verification, as part of Continuous Delivery, addresses the increased need for application reliability of production systems with intelligent and automated Quality Gates placed in the different application lifecycle/release stages. The verification steps thereby validate typical quality attributes like Functionality, Security or Performance (see image below).
Applying Continuous Verification principles to the pipeline allows SRE teams to stop/break software delivery when it shows quality regression in early stages (development, integration, …). The same mechanism is also useful for evaluating the health of the production after a fresh deployment and for deciding if either the new version should be rolled out to all instances or if a rollback should be triggered.
This blog post aims to illustrate three key challenges related to Continuous Verification by answering the following practical questions:
- How to balance between delivery speed and accurate verification?
- Which actions increase application reliability throughout all stages?
- Why have SREs to be involved to manage the pipeline?
Continuous Delivery starts with the Artifact
The Artifact Repository is often defined as the “technical contract“ between Continuous Integration and the Continuous Delivery Pipeline. The Continuous Integration pipeline produces artifacts in a structured way, which at the end, will be stored in an artifact repository. In fact, once an artifact is stored in the repository we can assume that:
- The application is built and packaged
- Test coverage validation is completed through unit tests, static code analysis, etc.
- Software components vulnerability checks are done
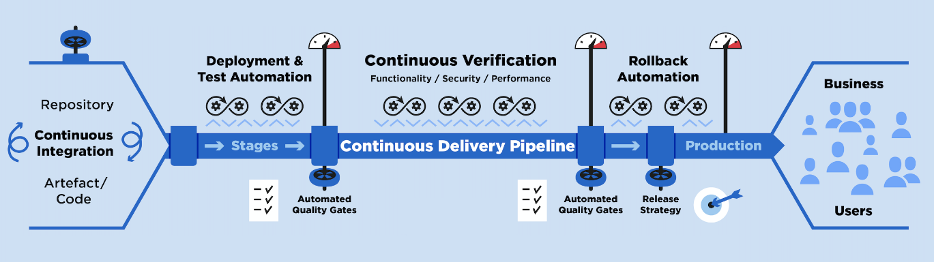
Continuous Delivery Pipeline key principles
At the base of moving the Artifact quickly into production, the pipeline which transports it needs to be reliable and designed to handle the high frequency of delivery. Here are a few high-level principles, which also give you confidence to ship with high frequency:
- Deploy to every stage (development/integration/production) using the same logic: reuse the templates and workflows used to deploy to your pre-production environment as well as to deploy to the production cycle.
- Failing fast: Keep in mind that a failed deployment in a pre-prod stage is one failed prod deployment less.
- Define pipelines and workflows to be idempotent: You should be able to run your pipelines and workflows as many times as possible, without creating problems with actions/steps done multiple times in a row.
- Manage all configuration in an appropriate way: Get an appropriate structure to manage the configuration for different services, environments. Use version control, use a secret manager to store secrets safely.
- Make database migrations part of your pipeline: This will make sure that your database has always the right structure
- Ensure it is your complete SRE team’s mission/responsibility to analyse what caused failures and continuously improve the pipeline.
- … and an obvious last point: keep your pipelines versioned, so that you can, whenever something goes wrong, rollback the pipeline definition.
Continuous Verification strategies
By increasing the overall automated verification coverage, of course all integrated into your pipeline, the delivery to production is ensured to stay on point by keeping the delivery speed high. Ideally, each stage has some specific verification: in a development stage verify functionality (component tests) and verify deployment strategies and general reliability aspects in an integration environment.
The quality gates are typically supplied through data coming from observability solutions or log events (also see our previous post on SLO Engineering).
The criteria to pass or fail a quality gate are either defined through your thresholds or determined through Machine Learning Algorithms. The main idea behind applying machine learning algorithms to the observability data and log events is to compare the actual state (performance, functionality, …) to what was defined as normal. Examples:
- Based on timeseries/signals (Number of successful calls, response time of API-endpoints, …) the signals 15 minutes prior the deployment are compared with the signals shown the first 15 minutes after the deployment.
- Based on log events, an increase of error-codes/exception frequency can be detected.
These kinds of verifications are typically coupled with the deployment strategy in use. For example, in the case of a canary deployment, the quality gates should check on the regression of the new instance as opposed to the existing instances.
In early stages, quality gates may validate database migrations and successful application start-up. In an integration stage, the quality gate focus on applying the release strategy and test functionality against regression, based on a systematic applied load (Performance or automated functional tests).
Delivery Speed vs. Verification Coverage
Nevertheles, every additional quality gate may throttle the throughput of the pipeline (manual approvals are also contributing to this). If the circumstances require faster shipment of features to production, the pipelines may need some remodelling and adjustment.
For example, you can decide for what it is called “Shift Right Testing” which means opting for performance and functionality regression verifications only in production (see footnote 5), with the trade-off of a lower user-experience for a few users.
Of course, this requires a high maturity of the observability toolchain and the SRE team in general.
Final Thoughts
In reality, we observe that the majority of organisations have often built their pipelines without Continuous Verification. But since today SREs and DevOps team members know how their application performs and its weak spots (from Observability data and release experience in particular), they should be able to address issues by inserting the right quality gates into the pipeline.
Yet, managing static thresholds in the pipeline is usually prone to error. It requires a high effort of maintenance and does not cover dynamic and frequent changes in application. By introducing Machine Learning capabilities either offered by the hopefully already leveraged observability suite (see footnote 4) or the continuous delivery tooling chain, the analysis of the high number of signals and events is automated and ready for future changes.
Please let us know if you have comments or would like to understand how Digital Architects Zurich can help you build the Digital Highway for Software Delivery. We can also provide training and engineering power for your team to effectively set-up Site Reliability Engineering (SRE), Continuous Delivery pipelines and AI-driven Continuous Verification.
Foot notes/References:
- Site Reliability Engineering Workbook, Chapter 3 – SLO Engineering Case Studies (McCormack and Bonnell, 2018)
- Effective SRE: how to democratize and apply Site Reliability Engineering in your organisation (Digital Architects Zurich, 2020)
- Effective SRE: SLO Engineering and Error budget (Digital Architects Zurich, 2020)
- Effective SRE Tooling for self-service monitoring and Analytics (Digital Architects Zurich, 2020)
- Gartner “DevOps Success Requires Shift Right Testing”